Recently, autoregressive (AR) video diffusion models have achieved remarkable performance. However, due to their limited training durations, a train-test gap emerges when testing at longer horizons, leading to rapid visual degradations.
Following Self Forcing, which studies the train-test gap within the training duration, this work studies the train-test gap beyond the training duration, i.e., the gap between the limited horizons during training and open-ended horizons during testing. Since open-ended testing can extend beyond any finite training window, and long-video training is computationally expensive, we pursue a training-free solution to bridge this gap.
To explore a training-free solution, we conduct a systematic analysis of AR cache maintenance. These insights lead to Rolling Sink. Built on Self Forcing (trained on only 5s clips), Rolling Sink effectively scales the AR video synthesis to ultra-long durations (e.g., 5-30 minutes at 16 FPS) at test time, with consistent subjects, stable colors, coherent structures, and smooth motions. As demonstrated by extensive experiments, Rolling Sink achieves superior long-horizon visual fidelity and temporal consistency compared to SOTA baselines.
Generating a long video (e.g., a movie) typically requires a multi-shot input, i.e., a sequence of prompts. Each shot typically corresponds to a single prompt, and can vary from few seconds to minutes, even hours long. For instance, Steve McQueen's Hunger begins with a classic 16.5 minutes dialogue shot (YouTube link, from 1:00 to 17:30) between Bobby Sands and the priest. This motivates open-ended video generation.
Though large video diffusion models (e.g., Sora, Wan, Kling, Veo, Gen) have achieved remarkable performance, they usually denoise all frames simultaneously, making them incompatible with such open-ended setting. In contrast, autoregressive (AR) video diffusion models architecturally enables open-ended video generation by continuously predicting the next-frame (or next-block) conditioned on previous ones.
However, AR video diffusion models are typically trained on limited and fixed durations (e.g., 5s in Self Forcing). When extrapolating to long horizons, especially beyond the training duration, these models often suffer from rapid visual degradation.
Such AR drift is commonly attributed to error accumulation. We further interpret it as a train-test gap between the limited-horizon training and open-ended testing.
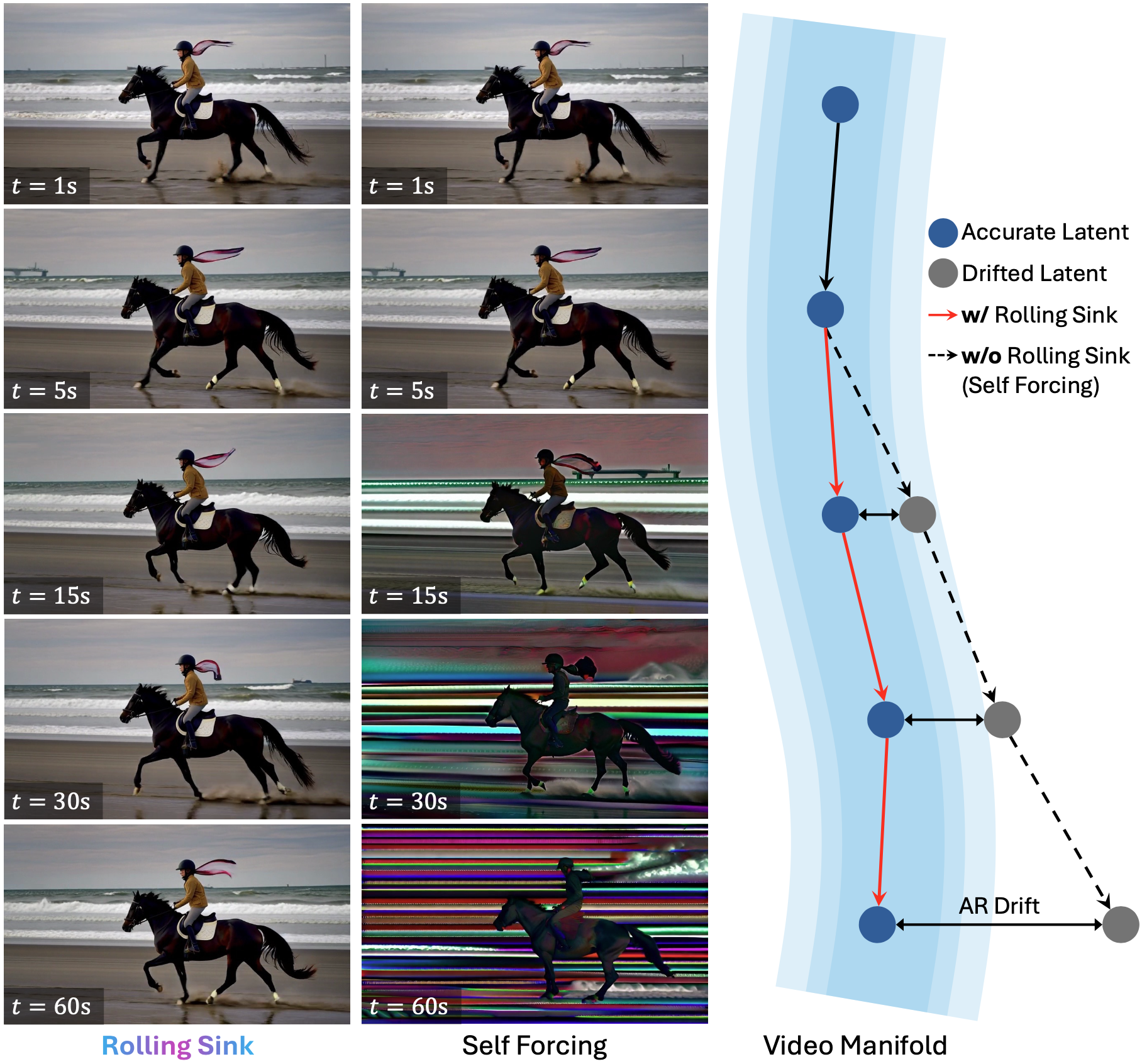
Indeed, training on longer videos can mitigate this gap. However, as long as the training is conducted on finite-length clips, the open-ended testing can always exceed the training window, and long-horizon drift can still occur. This motivates a training-free approach to bridge limited-horizon training and open-ended testing. The goal is to constantly reproduce the impressive video synthesis quality, exhibited when testing within the training duration, over ultra-long horizons.
Since the prompt embedding stays fixed throughout AR video synthesis, and the initial noise for each block is always drawn from the same Gaussian distribution, the context (i.e., cache) is the major factor of long-horizon AR drift. Thus, for maintaining drift-free during open-ended testing, the AR cache should stay consistent with its within-duration behavior/characteristic.
Concretely, building on Self Forcing, we aim to keep the AR cache consistent with its within-duration behavior under a strictly bounded capacity $K$. This behavior includes: ① minimally drifted: all cached blocks should be drift-free (i.e., no over-saturated colors, no collapsed structures, etc.); and ② sliding in both indices and semantics: the cached blocks' time indices are assigned from a fixed-length sliding window on a global axis $i\in[0,\infty)$ immediately preceding the current block (i.e., Sliding Indices), similarly, the cached blocks' semantic content is also updated as a moving slice from a global video manifold that lasts endlessly (i.e., Sliding Semantics).
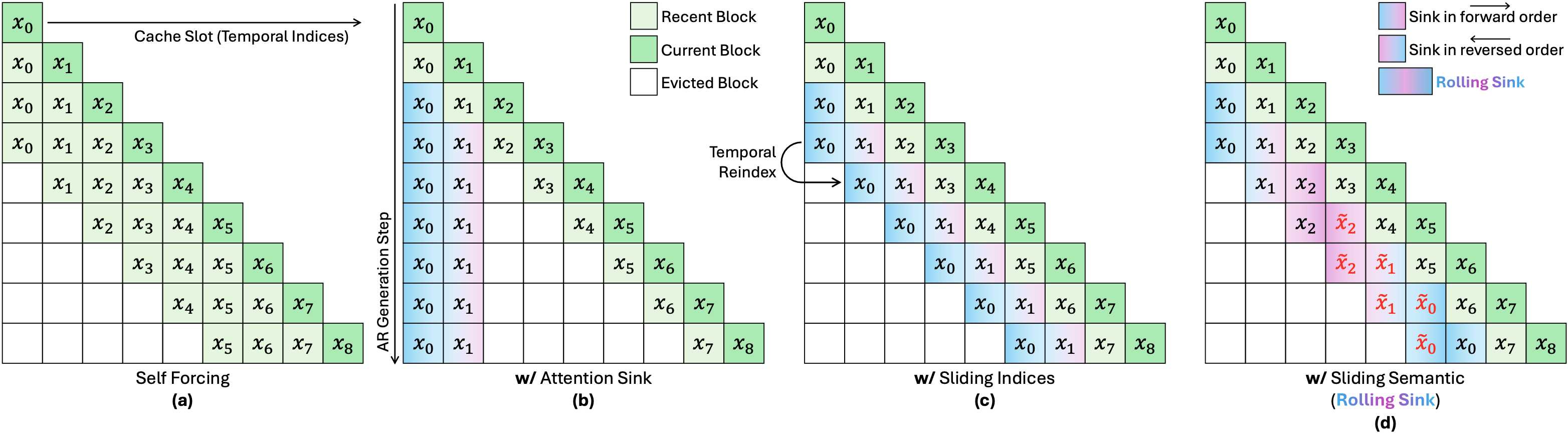
ⓐ The caching mechanism of Self Forcing, the total cache capacity $K$ is strictly bounded for streaming efficiency.
ⓑ We firstly apply Attention Sink (i.e., pinning the first $S$ blocks as sink blocks where both the time indices and semantics are static), and analyze the effect of different sink ratios ($\frac{S}{K}$).
ⓒ Sliding Indices: Treating the time indices as a global axis $i\in[0,\infty)$, at each AR step $i$, we shift sink blocks' time indices as a fixed-length (i.e., $S$) sliding window on this axis right before the recent and current blocks.
ⓓ Sliding Semantics: Ideally, the sink blocks' semantic content should also slide along a drift-free, global video manifold that lasts endlessly.
Since finite-length training cannot naturally realize this, we approximate the true semantic sliding by rolling the sink content (i.e., at each AR step, we update the sink blocks' semantic content with a rolling segment from the within-duration history).
Finally, we propose ⓓ and name it Rolling Sink. For clarity, here we set $K=3$ and $S=2$.
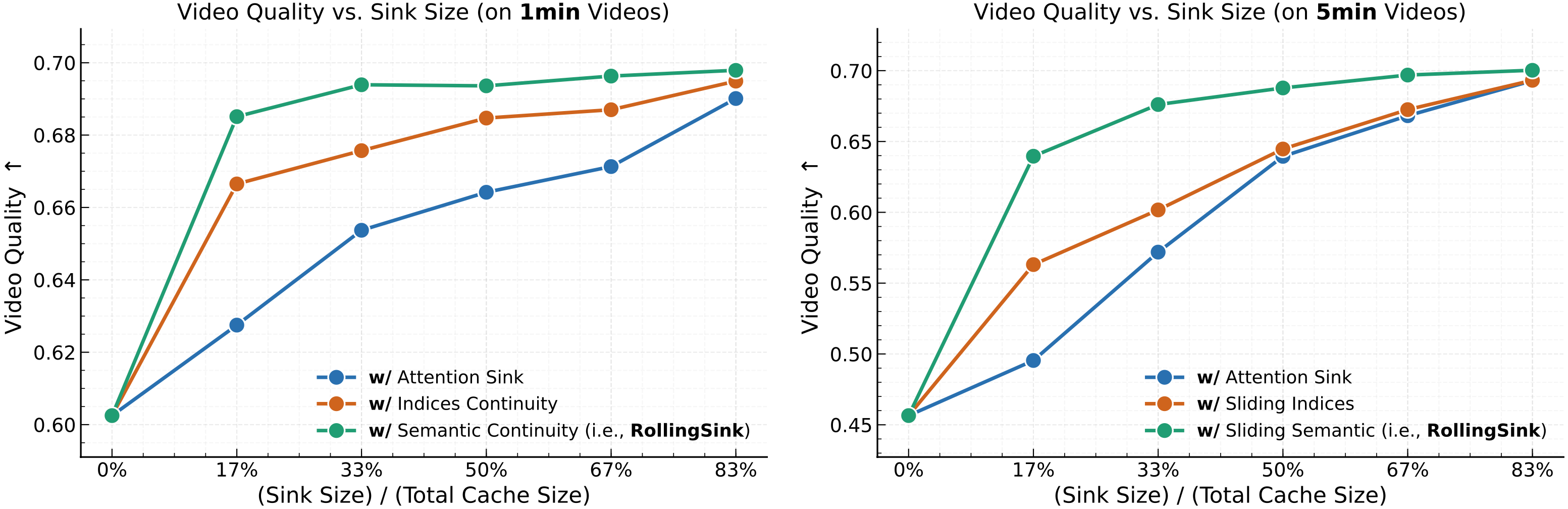
As illustrated ⬅️, the video quality is consistently improved during our systematic analysis and the derived Rolling Sink yields the best performance (particularly when $\frac{S}{K}=83\%$).
The video quality score is the averaged score across all dimensions tested using VBench-Long.
Larger sink sizes stabilize colors. But noticeable AR drift still persists, e.g., frame flickers. Here we set $t=60\text{s}$.

Introducing Sliding Indices reduces AR drift, most noticeably by mitigating flicker. However, noticeable drift still persists, e.g., inconsistencies.
w/o Sliding Semantics
w/ Sliding Indices

Initial frame
w/ Sliding Semantics
w/ Sliding Indices
Approximating Sliding Semantics via rolling the semantic content of sink blocks further mitigates the AR drift, noticeably illustrated as improved consistencies. Here we also set $t=60\text{s}$.
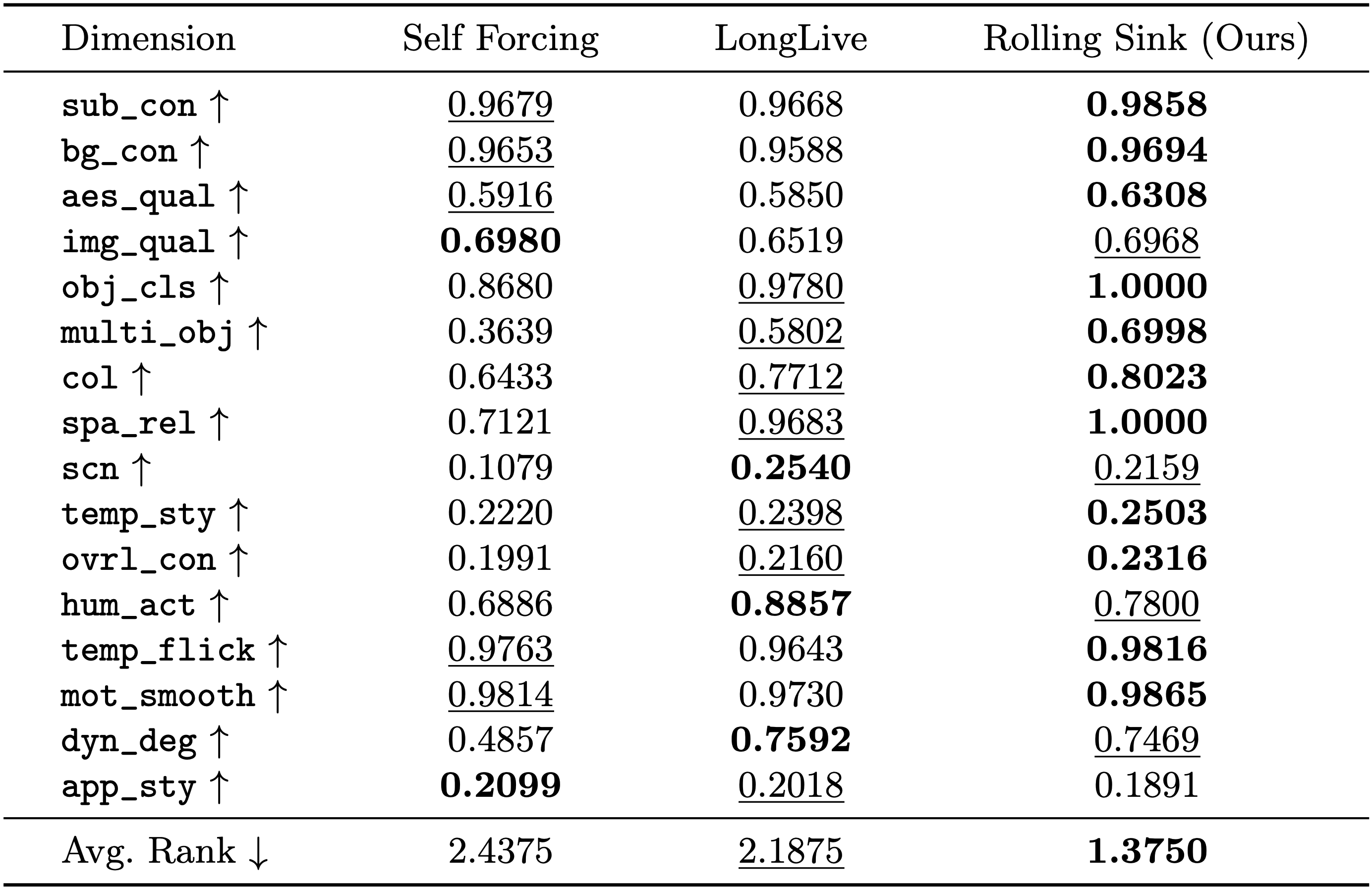
Quantitative comparison of Rolling Sink with SOTA baselines on 1-minute AR video synthesis using VBench-Long.
Quantitative comparison on 5-minute AR video synthesis.
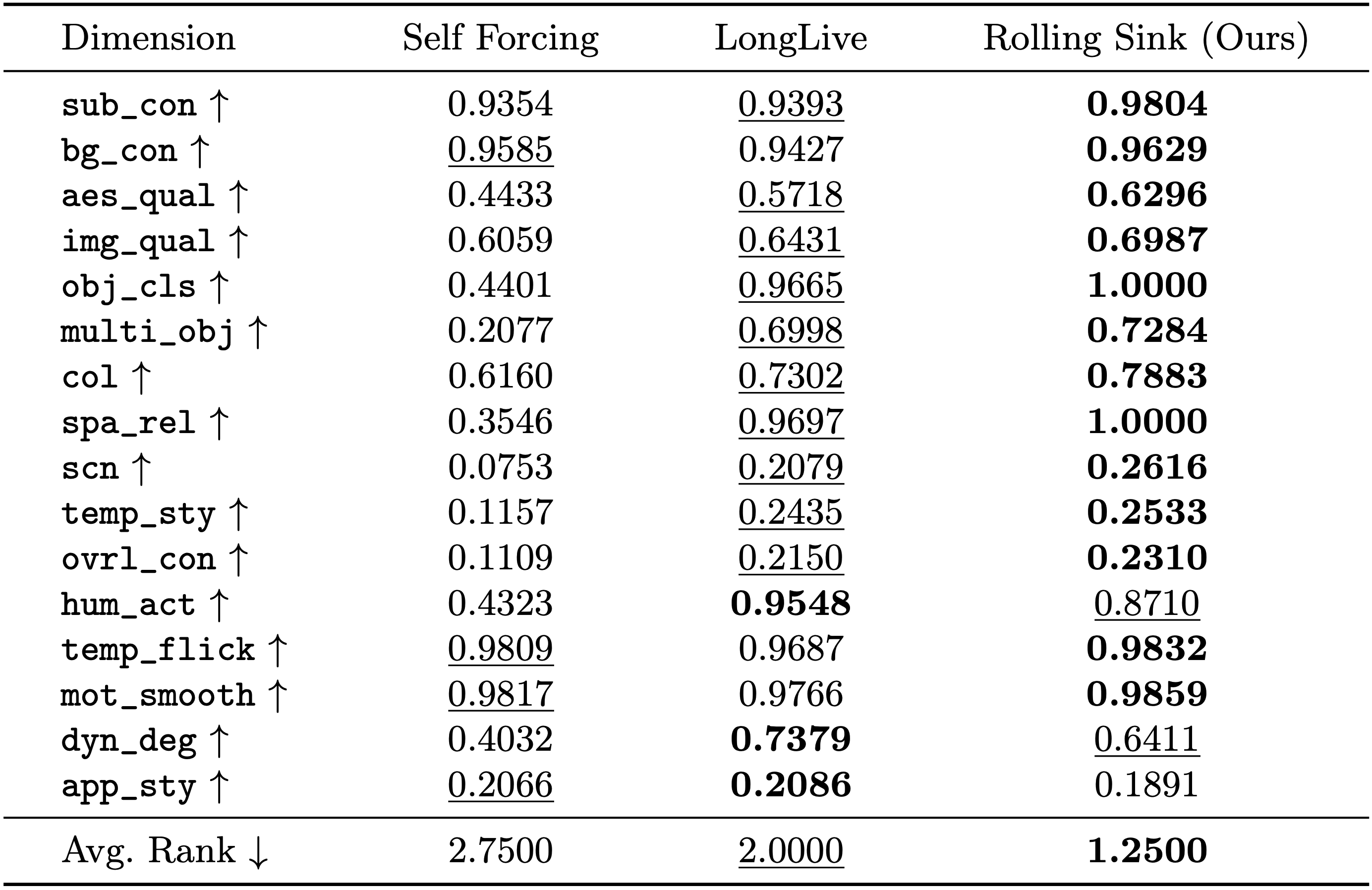

On both settings, the proposed Rolling Sink achieves the best average rank and obtains the top scores on most dimensions, reflecting the reduced drift and improved visual quality when testing far beyond the training window. Notably, though Rolling Sink is built on top of Self Forcing and requires no additional training, it yields substantial performance gains.
Here, to ensure all methods are trained on 5s clips for fairness, LongLive's LoRA isn't loaded. Please see paper's Sec. F for the comparisons with LongLive (w/ LoRA).
Please consider citing our paper if you find it useful in your research :-)
@article{li2026rolling,
title={Rolling Sink: Bridging Limited-Horizon Training and Open-Ended Testing in Autoregressive Video Diffusion},
author={Li, Haodong and Liu, Shaoteng and Lin, Zhe and Chandraker, Manmohan},
journal={arXiv preprint arXiv:2602.07775},
year={2026}
}